



Maciej Ławryńczuk

Badania
3. Sieci neuronowe w regulacji predykcyjnej
Modelowanie jest bardzo ważnym etapem projektowania algorytmu regulacji. Choć zasada regulacji predykcyjnej jest ogólna, nie ogranicza rodzaju modelu użytego do predykcji, wybór modelu istotnie wpływa na złożoność algorytmu, a tym samym na możliwości jego zastosowania. Ocenia się, że modelowanie może zająć nawet do 90% czasu projektowania algorytmu [ML99]. Należy wymienić dwie klasy modeli:
- modele fizykalne (fenomenologiczne),
- modele empiryczne.
Z teoretycznego punktu widzenia zawsze można sformułować dokładny model fizykalny procesu (zestaw równań różniczkowych i algebraicznych) [L90, M95]. Niestety, bardzo często opracowanie i weryfikacja takiego modelu mogą okazać się zbyt trudne dla osób niebędących technologami, w tym również dla automatyków. Co więcej, modele fizyczne mogą być zbyt skomplikowane, aby mogły być bezpośrednio zastosowane w algorytmie regulacji predykcyjnej. Dlatego też bardzo często stosuje się modele empiryczne, których struktura jest wybierana arbitralnie, natomiast parametry wyznaczane są wyłącznie na podstawie danych [N01]. Choć parametry modelu nie mają interpretacji fizycznej, identyfikacja nie wymaga wiedzy technologicznej. Spośród wielu istniejących klas modeli empirycznych bardzo interesujące właściwości mają modele neuronowe [DKR+00, H99, KOU94, O06, R96, R05, ŻBJ96]. Ich zalety można scharakteryzować następująco:
- Modele neuronowe są dokładne.
- Mają one zwykle mają niewielką (umiarkowaną) liczbę parametrów, ich liczba nie rośnie gwałtownie przy wzroście rzędu dynamiki modelu oraz liczby zmiennych wejściowych, wyjściowych i (lub) stanu.
- Dostępnych jest wiele efektywnych algorytmów uczenia modeli neuronowych oraz doboru (optymalizacji) struktury. Modele uczone są wyłącznie na podstawie danych, nie jest wymagana wiedza technologiczna dotycząca procesu.
- W przeciwieństwie do modeli fizykalnych modele neuronowe nie zawierają żadnych równań różniczkowych ani algebraicznych, które należy cyklicznie rozwiązywać w algorytmie regulacji predykcyjnej. Rozwiązywanie takich równań może być złożone obliczeniowo. Co więcej, podczas obliczeń prawdopodobne jest wystąpienie problemów numerycznych, np. złego uwarunkowania.
- Modele neuronowe mogą być stosunkowo łatwo wykorzystane w nieliniowych algorytmach regulacji predykcyjnej, ich implementacja nie jest bardzo złożona.
Poniżej krótko przedstawiono kilka rodzajów modeli neuronowych. Wszystkie modele być zastosowane we wszystkich omówionych suboptymalnych algorytmach regulacji predykcyjnej z linearyzacją modelu (algorytmy SL i NPL) oraz z linearyzacją trajektorii prognozowanej (algorytmy NPLT i NPLTP), zarówno w wersji numerycznej (z optymalizacją kwadratową) oraz w wersji analitycznej.
3.1. Sieci neuronowe typu perceptronowego
Choć opracowano bardzo wiele różnych typów sieci neuronowych, największym zainteresowaniem cieszy się sieć jednokierunkowa nazywana często perceptronem wielowarstwowym (ang. Multi Layer Perceptron, MLP) lub po prostu siecią perceptronową. Struktura najczęściej wykorzystywanej dwuwarstwowej sieci neuronowej z jedną warstwą ukrytą (ang. Double Layer Perceptron, DLP), realizującej ogólny model dynamiczny $$ y(k)=f(\boldsymbol{x}(k))=f(u(k-\tau),\ldots,u(k-n_{\mathrm{B}}),y(k-1),\ldots,y(k-n_{\mathrm{A}}))$$ została przedstawiona na rys. 7. Sieć ma \(n_{\mathrm{A}}+n_{\mathrm{B}}-\tau+1\) wejść, \(K\) neuronów ukrytych o nieliniowej funkcji aktywacji \(\varphi \colon \mathbb{R} \rightarrow \mathbb{R}\), jeden liniowy neuron wyjściowy (sumator) oraz jedno wyjście \(y(k)\). Jako funkcję aktywacji najczęściej stosuje się sigmoidalną funkcję unipolarną $$\begin{equation} \varphi (x)=\frac{1}{1+\exp(-\beta x)} \nonumber \end{equation}$$ lub bipolarną $$\begin{equation} \varphi (x)=\tanh(\beta x)=\frac{1-\exp(-\beta x)}{1+\exp(-\beta x)} \nonumber \end{equation}$$ gdzie \(\beta\) jest parametrem funkcji aktywacji, zwykle przyjmuje się \(\beta=1\).
Sieć ma strukturę jednokierunkową, przepływ sygnałów odbywa się tylko w jednym kierunku, od wejścia do wyjścia. Dodatkowe wejścia pierwszej i drugiej warstwy, na które podany jest stały sygnał jednostkowy, są tzw. wejściami polaryzacji. Wagi pierwszej warstwy oznaczone są przez \(w^1_{i,j}\), gdzie \(i=1,\ldots,K\), \(j=0,\ldots,n_{\mathrm{A}}+n_{\mathrm{B}}-\tau+1\), wagi drugiej warstwy oznaczone są przez \(w^2_i\), gdzie \(i=0,\ldots,K\). Wyjście sieci jest opisane równaniem $$\begin{equation} y(k)=w_{0}^{2}+\sum\limits_{i=1}^{K}w_{i}^{2}\varphi (z_i(k)) \label{w_yk_snmlp} %\nonumber \end{equation}$$ gdzie suma sygnałów dochodzących do \(i\)-tego neuronu ukrytego wyraża się wzorem $$\begin{align} z_i(k)&=w_{i,0}^{1}+\sum_{j=\tau}^{n_{\mathrm{B}}} w_{i,j-\tau+1}^{1}u(k-j)+\sum_{j=1}^{n_{\mathrm{A}}} w_{i,n_{\mathrm{B}-\tau+1+j}}^{1}y(k-j)\nonumber %\label{w_zik_snmlp} \end{align}$$
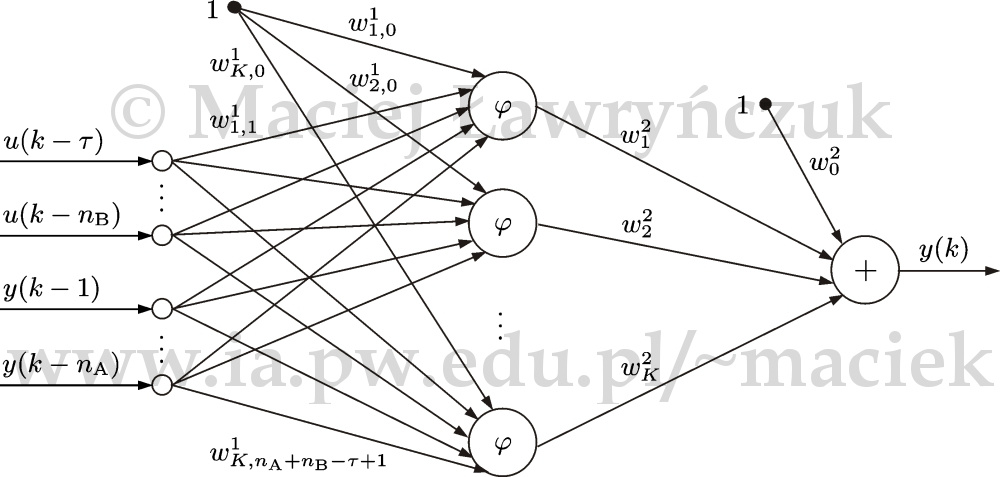
Udowodniono teoretycznie, że sieć perceptronowa o jednej warstwie ukrytej (przy odpowiedniej liczbie neuronów z sigmoidalną funkcją aktywacji w tej warstwie) może aproksymować dowolną funkcję ciągłą z zadaną dokładnością - jest ona doskonałym aproksymatorem funkcji wielu zmiennych [HSW89].
Identyfikacja modelu neuronowego składa się z trzech etapów: wyznaczenia struktury (wejść i liczby neuronów ukrytych), uczenia (optymalizacji parametrów - wag) oraz weryfikacji. W praktyce często wyznacza się szereg modeli i wybiera najlepszy z punktu widzenia dokładności i liczby parametrów. Uczenie modelu polega na minimalizacji sumy kwadratów błędów modelu (ang. Sum of Squared Errors) $$\begin{equation} \mathrm{SSE}=\sum_{k=1}^{n_{\mathrm{p}}} (y^{\mathrm{mod}}(k)-y(k))^2 %\nonumber \label{w_sse} \end{equation}$$ gdzie \(y^{\mathrm{mod}}(k)\) jest sygnałem wyjściowym modelu dla chwili \(k\), natomiast \(y(k)\) jest zarejestrowanym wzorcem uczącym, \(n_{\mathrm{p}}\) jest liczbą próbek. Podczas uczenia modelu neuronowego wykorzystuje się zazwyczaj różne gradientowe metody minimalizacji bez ograniczeń: algorytm najszybszego spadku, gradientów sprzężonych, zmiennej metryki lub Levenberga-Marquardta [O06]. Niekiedy również (szczególnie do inicjalizacji) można zastosować podejścia heurystyczne, takie jak algorytmy genetyczne czy też symulowane wyżarzanie [R05].
Bazujący na perceptronowych modelach neuronowych algorytm regulacji predykcyjnej typu SL opisano w pracy [Ł14a, T07, TŁ06], algorytm NPL w pracach [Ł14a, Ł08a, Ł07, T07, TŁ06], algorytm NPLT w pracach [Ł14a, Ł12], natomiast algorytm NPLTP w pracach [Ł14a, Ł11c]. Algorytmy analityczne przedstawiono w pracach [Ł14a, Ł09a].
3.2. Radialne sieci neuronowe
Drugim bardzo często stosowanym rodzajem sieci neuronowych są struktury o radialnych funkcjach bazowych (ang. Radial Basis Function, RBF), nazywane krótko sieciami radialnymi. W sieciach perceptronowych stosuje się zazwyczaj sigmoidalne funkcje aktywacji. Wszystkie neurony aktywne uczestniczą w formowaniu sygnału wyjściowego sieci, są one aproksymatorami globalnymi [O96]. Podejściem alternatywnym jest aproksymacja lokalna, w której sygnał wyjściowy sieci jest sumą odwzorowań lokalnych. W sieciach radialnych poszczególne neurony są aktywne tylko w pewnym obszarze przestrzeni danych.
Struktura radialnej sieci neuronowej została przedstawiona na rys. 8. Jest ona podobna do pokazanej na rys. 7 sieci perceptronowej, gdyż jest to również sieć jednokierunkowa, ma te same wejścia, \(K\) neuronów ukrytych oraz jedno wyjście \(y(k)\). Sieć ma jednak tylko jedną warstwę wag, są one oznaczone symbolem \(w_i\), gdzie \(i=0,\ldots,K\), neurony ukryte nie mają wejść polaryzacji. Dla najpopularniejszej funkcji aktywacji Gaussa wyjście sieci jest opisane równaniem $$\begin{equation} y(k)=w_{0}+\sum\limits_{i=1}^{K}w_{i}\exp \left ( -\frac{1}{2\sigma^2_i} z_i(k) \right ) \label{w_yk_snrbf} %\nonumber \end{equation}$$ gdzie suma sygnałów dochodzących do \(i\)-tego neuronu ukrytego wyraża się wzorem $$\begin{align} z_i(k)&=\sum_{j=\tau}^{n_{\mathrm{B}}} (u(k-j)-c_{i,j-\tau+1})^2+\sum_{j=1}^{n_{\mathrm{A}}} (y(k-j)-c_{i,n_{\mathrm{B}-\tau+1+j}})^2\nonumber %\label{w_yk_snmlp} \end{align}$$ Parametry \(\sigma_i\) decydują o zakresie działania kolejnych funkcji bazowych, natomiast wektory \(\left [c_{i,1} \ldots c_{i,n_{\mathrm{A}}+n_{\mathrm{B}}-\tau+1} \right ]^{\mathrm{T}}\) określają położenie centrów funkcji bazowych, przy czym \(i=1,\ldots,K\).
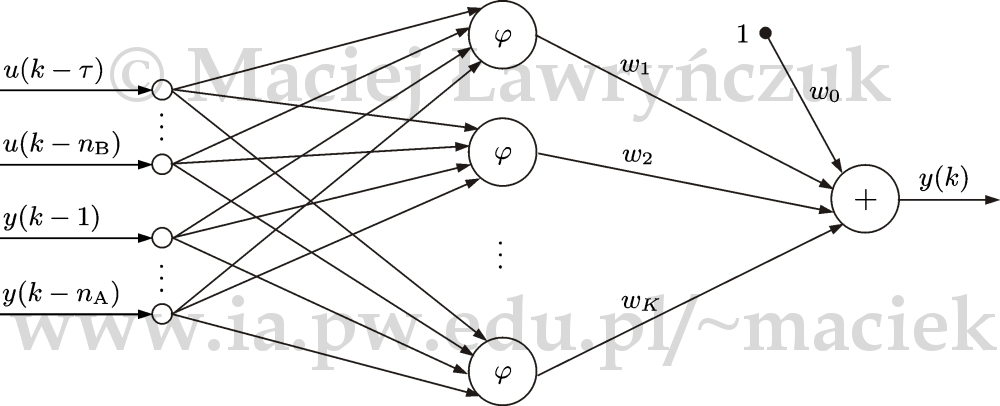
Analogicznie jak klasyczna sieć perceptronowa, również sieć radialna o jednej warstwie ukrytej (przy odpowiedniej liczbie neuronów) jest doskonałym aproksymatorem funkcji wielu zmiennych [PS91].
Można zauważyć, że zgodnie z równaniem \eqref{w_yk_snmlp}, wyjście sieci perceptronowej jest nieliniową funkcją parametrów (wag). Do jej uczenia (miminalizacji funkcji błędu \eqref{w_sse}) trzeba zastosować nieliniową optymalizację, w której podstawowym problemem jest występowanie minimów lokalnych. Zgodnie z równaniem \eqref{w_yk_snrbf}, wyjście sieci radialnej jest liniowo zależne od wag, minimalizowana funkcja celu jest kwadratowa ze względu na wagi. Do uczenia sieci radialnych można zastosować bardzo efektywny algorytm hybrydowy, w którym wagi są obliczane w wyniku rozwiązania zadania najmniejszych kwadratów, natomiast centra są wyznaczane w wyniku rozwiązania zadania nieliniowej optymalizacji. Niestety, konsekwencją lokalnej aproksymacji sieci radialnej jest zazwyczaj większa, czasami dużo większa, liczba neuronów (a tym samym parametrów całego modelu) niż sieci perceptronowej.
Bazujący na radialnych modeli neuronowych algorytm regulacji predykcyjnej typu NPL opisano w pracy [ŁT07].
3.3. Neuronowe modele kaskadowe
Bardzo często wiadomo, że właściwości nieliniowe procesu są typu statycznego, tzn. nieliniowa jest charakterystyka statyczna czujnika lub elementu wykonawczego, natomiast dynamika jest (w przybliżeniu) liniowa. Warto wówczas zastosować modele szeregowe (kaskadowe) Hammersteina lub Wienera o strukturze przedstawionej na rys. 9 [J04]. Oba modele złożone są z nieliniowego członu statycznego i liniowego członu dynamicznego: w strukturze Hammersteina człon nieliniowy znajduje się na wejściu, w modelu Wienera - na wyjściu. Choć przyjęcie struktury szeregowej ma dość restrykcyjny charakter, to omawiane modele bardzo często stosuje się w praktyce [J04]. W neuronowych modelach Hammersteina i Wienera w nieliniowych członach statycznych stosuje się sieci neuronowe, przede wszystkim typu perceptronowego lub radialnego. Neuronowe modele szeregowe są dużo bardziej dokładne i mają znacznie lepsze właściwości interpolacyjne oraz ekstrapolacyjne niż najprostsze struktury z wielomianowymi członami nieliniowymi [J04]. Co więcej, szeregowe modele neuronowe mają znacznie mniej parametrów niż modele wielomianowe, szczególnie w przypadku wielowymiarowym.
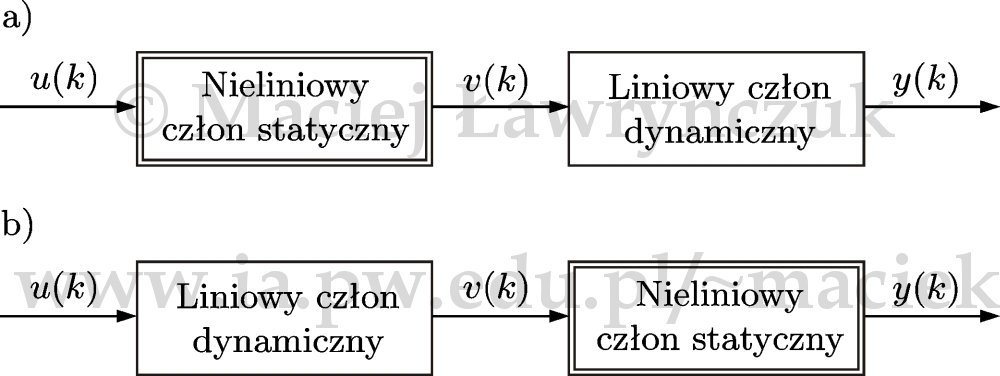
Zakładając, że w nieliniowym członie statycznym modelu Hammersteina stosuje się sieć perceptronową opisaną równaniem $$\begin{equation} v(k)=w_{0}^{2}+ \sum_{i=1}^{K} w_{i}^{2}\varphi(w_{i,0}^{1}+w_{i,1}^{1}u(k))\label{w_ham1} \end{equation}$$ gdzie \(v(k)\) jest sygnałem pośrednim między członem statycznym a dynamicznym. Wagi sieci oznaczone są symbolami \(w_{i,j}^{1}\) dla \(i=1,\ldots,K\), \(j=0,1\) oraz \(w_{i}^{2}\) dla \(i=0,\ldots,K\). Liniowy człon dynamiczny opisany jest równaniem $$\begin{equation} y(k)=\sum_{l=\tau}^{n_{\mathrm{B}}} b_lv(k-l)-\sum_{l=1}^{n_{\mathrm{A}}}a_ly(k-l)\label{w_ham2} \end{equation}$$ Na podstawie równań \eqref{w_ham1} oraz \eqref{w_ham2}, wyjście neuronowego modelu Hammersteina można przedstawić w następującej postaci $$\begin{equation} y(k)=\sum_{l=\tau}^{n_{\mathrm{B}}} b_l \left( w_{0}^{2}+ \sum_{i=1}^{K} w_{i}^{2}\varphi(w_{i,0}^{1}+w_{i,1}^{1}u(k-l)) \right)-\sum_{l=1}^{n_{\mathrm{A}}}a_ly(k-l)\nonumber \end{equation}$$
Analogicznie, wyjście modelu Wienera z perceptronową siecią neuronową w roli nieliniowego członu statycznego opisane jest równaniem $$\begin{align} y(k)&=w_{0}^{2}+\sum_{i=1}^{K}w_{i}^{2}\varphi(w_{i,0}^{1}+w_{i,1}^{1}v(k))\nonumber\\ &=w_{0}^{2}+ \sum_{i=1}^{K} w_{i}^{2}\varphi\left(w_{i,0}^{1}+w_{i,1}^{1}\left(\sum_{l=\tau}^{n_{\mathrm{B}}} b_lu(k-l)-\sum_{l=1}^{n_{\mathrm{A}}}a_lv(k-l)\right)\right)\nonumber \end{align}$$ Oczywiście, w członie statycznym modeli kaskadowych można również zastosować radialne sieci neuronowe.
Bazujący na neuronowych (perceptronowych) modelach Hammersteina algorytm regulacji predykcyjnej typu SL opisano w pracy [Ł14a], algorytm NPL w pracach [Ł14a, Ł10b], algorytmy NPLT i NPLTP w pracy [Ł14a]. Implementację algorytmu SL dla neuronowych (perceptronowych) modeli Wienera podano w pracy [Ł14a], implementację algorytmu NPL w pracach [Ł14a, Ł10c], implementację algorytmów NPLT i NPLTP w pracy [Ł14a, Ł13]. Dzięki specyficznej strukturze modeli kaskadowych można również wyprowadzić algorytm regulacji predykcyjnej z Nieliniową Predykcją i Uproszczoną Linearyzacją (NPUL). Implementację algorytmu NPUL dla neuronowego modelu Hammersteina podano w pracy [Ł14a], przypadek modelu modelu Wienera omówiono w pracach [Ł14a, Ł13].
3.4. Neuronowe modele w przestrzeni stanu
Pomimo tego, że obecnie w zastosowaniach przemysłowych dominują algorytmy oparte na modelach typu wejście-wyjście, algorytmy bazujące na modelach w przestrzeni stanu (przede wszystkim liniowych) są również wykorzystywane, są one dostępne w komercyjnych pakietach oprogramowania oferowanych do zastosowań przemysłowych [M02, QB03, T07, T02]. Warto również podkreślić, że opis w przestrzeni stanu jest podejściem bardziej ogólnym, wygodnym do analizy teoretycznej; podczas badania stabilności i odporności algorytmów regulacji predykcyjnej wykorzystuje się praktycznie wyłącznie opis w przestrzeni stanu [MRR+00].
Model nieliniowego procesu w przestrzeni stanu o jednym wejściu \(u\) i jednym wyjściu \(y\) ma następującą postać $$\begin{align} x(k+1)&=f(x(k),u(k))\nonumber\\ y(k)&=g(x(k))\nonumber \end{align}$$ gdzie \(x(k)=\left [x_1(k) \ldots x_{n_{\mathrm{x}}}(k) \right ]\) jest wektorem stanu. Na rys. 10 przedstawiono ogólną strukturę modelu neuronowego w przestrzeni stanu. Model złożony jest z dwóch sieci neuronowych: pierwsza z nich realizuje nieliniowe równanie stanu, druga - nieliniowe równanie wyjścia. Pierwsza sieć ma \(n_{\mathrm{x}}+1\) wejść oraz \(n_{\mathrm{x}}\) wyjść. Druga sieć ma \(n_{\mathrm{x}}\) wejść oraz jedno wyjście.
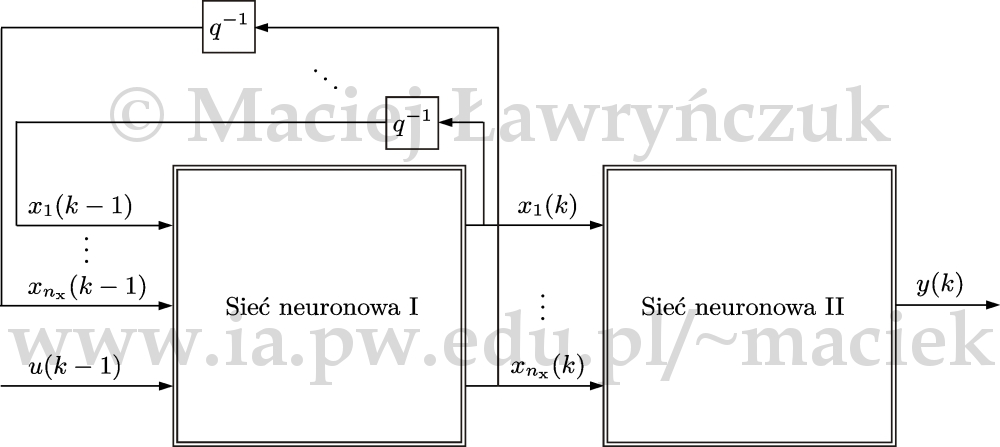
Bazujące na neuronowych (perceptronowych) modelach w przestrzeni stanu algorytmy SL, NPLT i NPLTP omówiono w pracy [Ł14a], algorytm NPL przedstawiono w pracach [Ł14a, Ł10d].
3.5. Zespoły modeli neuronowych
Z punktu widzenia algorytmu regulacji predykcyjnej model można uznać za dobry tylko wówczas, gdy umożliwia on dokładne przewidywanie wartości sygnałów wyjściowych i (lub) zmiennych stanu na całym horyzoncie predykcji. Klasyczne modele omówione do tej pory (typu wejście-wyjście lub w przestrzeni stanu) w regulacji predykcyjnej zawsze są stosowane rekurencyjnie. Występuje wówczas tzw. zjawisko propagacji błędów predykcji: błąd predykcji (różnica między sygnałem prognozowanym a sygnałem rzeczywistego procesu) na początku horyzontu predykcji jest dość mały, lecz powiększa się on w kolejnych chwilach horyzontu. Zjawisko takie występuje przy błędach modelowania oraz przy szumach pomiarowych. Błędy modeli bardzo często spowodowane są przyjęciem zbyt niskiego rzędu dynamiki. Zazwyczaj jest to działanie celowe, gdyż rzeczywisty rząd dynamiki procesu jest wysoki, często trudno jest określić rzeczywisty rząd dynamiki.
Wyeliminowanie zjawiska propagacji błędów predykcji wymaga zastosowania modeli o specjalnej strukturze, uwzględniającej ich rolę (predykcja) w algorytmach regulacji predykcyjnej. Ogólną strukturę zespołu modeli (ang. multi-model) przedstawiono na rys. 11 [Ł14a]. Do predykcji stosuje się \(N\) niezależnych modeli składowych, każdy z nich wyznacza predykcję dla jednej chwili horyzontu predykcji. Jako modele składowe można zastosować sieci neuronowe perceptronowe lub radialne.
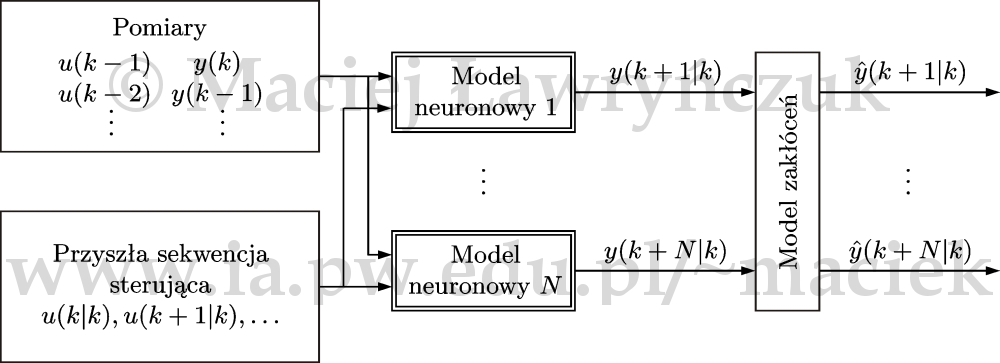
Dla nieliniowego procesu o jednym wejściu i jednym wyjściu, dla pierwszej chwili horyzontu predykcji (\(p=1\)), stosuje się model $$\begin{align} y(k+1|k)=f^1(&u(k-\tau+1),\ldots,u(k-n_{\mathrm{B}})\nonumber\\ &y(k),\ldots,y(k-n_{\mathrm{A}})) \nonumber \end{align}$$ dla kolejnej chwili (\(p=2\)) stosuje się model $$\begin{align} y(k+2|k)=f^2(&u(k-\tau+2),\ldots,u(k-n_{\mathrm{B}})\nonumber\\ &y(k),\ldots,y(k-n_{\mathrm{A}})) \nonumber \end{align}$$ W podobny sposób określa się modele składowe dla kolejnych chwil horyzontu predykcji. Ostatni z modeli ma postać $$\begin{align} y(k+N|k)=f^N(&u(k-\tau+N),\ldots,u(k-n_{\mathrm{B}})\nonumber\\ &y(k),\ldots,y(k-n_{\mathrm{A}})) \nonumber \end{align}$$ Predykcje sygnałów wyjściowych na horyzoncie predykcji (\(p=1,\ldots,N\)) można wyrazić jako funkcje $$\begin{align} \hat{y}(k+p|k)=f^p(&\underbrace{u(k-\tau+p|k),\ldots,u(k|k)}_{I_{\mathrm{uf}}(p)},\nonumber\\ & \underbrace{u(k-\max(\tau-p,1)),\ldots,u(k-n_{\mathrm{B}})}_{I_{\mathrm{up}}(p)},\nonumber\\ & \underbrace{y(k),\ldots,y(k-n_{\mathrm{A}})}_{n_{\mathrm{A}}+1})+d(k+p|k) \nonumber \end{align}$$ gdzie dla zespołu modeli \(I_{\mathrm{uf}}(p)=\max(p-\tau+1,0)\), \(I_{\mathrm{up}}(p)=n_{\mathrm{B}}-\max(\tau-p,1)+1\). Dzięki zastosowaniu modelu o specjalnej strukturze sygnały prognozowane nie zależą rekurencyjnie od predykcji dla wcześniejszych chwil horyzontu predykcji, co jest cechą szczególną wszystkich omówionych do tej pory modeli.
Reasumując, zalety zespołu modeli są następujące:
- Zespół modeli nie jest stosowany rekurencyjnie w algorytmie regulacji, błąd predykcji nie jest propagowany.
- Poszczególne modele składowe uczone są oddzielnie, bez rekurencji, jak zwykłe modele statyczne. Nie ma potrzeby identyfikacji pojedynczego, ale zwykle dużo bardziej skomplikowanego, modelu rekurencyjnego, którego zadaniem jest predykcja na całym horyzoncie.
- Rząd dynamiki modeli składowych tworzących zespół modeli może być niższy niż klasycznego (pojedynczego) modelu.
Bazujące na zespołach modeli neuronowych typu perceptronowego algorytmy NPLT i NPLTP omówiono w pracy [Ł14a], algorytm NPLT przedstawiono w pracach [Ł14a, Ł10a]. Implementację algorytmu NPLT dla zespołu złożonego z sieci radialnych podano w pracy [Ł09c].
3.6. Inne struktury modeli neuronowych
Oprócz opisanych powyżej modeli neuronowych opracowano szereg innych struktur neuronowych, posiadających interesujące właściwości. Jako przykłady można podać rekurencyjne sieci neuronowe (np. typu Elmana) [MC01, O06], sieci neuronowe z neuronami dynamicznymi [P08] czy też modele wektorów wspierających (ang. Support Vector Machines, SVM) [SS01], np. typu LS-SVM (ang. Least Squares Support Vector Machines) [SGB+02]. Wydaje się, że mogą być one również zastosowane w efektywnych obliczeniowo algorytmach regulacji predykcyjnej.

| Poprzednia strona: 2. Efektywne obliczeniowo nieliniowe algorytmy regulacji predykcyjnej | Następna strona: 4. Przykład 1: modelowanie i regulacja predykcyjna reaktora fermentacji |