



Maciej Ławryńczuk

Badania
6. Algorytmy regulacji predykcyjnej z aproksymacją neuronową
Cechą szczególną algorytmów regulacji predykcyjnej z aproksymacją neuronową jest brak bieżącej linearyzacji. Szczególnie efektywne obliczeniowo są algorytmy analityczne, gdyż aproksymator neuronowy bezpośrednio wyznacza współczynniki prawa regulacji.
6.1. Algorytm NPL z Aproksymacją Neuronową (NPLAN)
W klasycznym algorytmie NPL nieliniowy model procesu jest na bieżąco linearyzowany w aktualnym punkcie pracy. Przybliżenie liniowe modelu nieliniowego jest następnie stosowane do predykcji. Dzięki linearyzacji, wektor prognozowanych sygnałów wyjściowych jest liniową funkcją zmiennych decyzyjnych $$ \begin{equation} \hat{\boldsymbol{y}}(k)=\boldsymbol{G}(k)\triangle\boldsymbol{u}(k)+\boldsymbol{y}^{0}(k)\label{w_ypred_npl} \end{equation}$$ gdzie macierz \(\boldsymbol{G}(k)\) zawiera współczynniki odpowiedzi skokowej modelu zlinearyzowanego, trajektoria swobodna \(\boldsymbol{y}^{0}(k)\) jest obliczana na podstawie pełnego modelu nieliniowego.
Na rys. 23 przedstawiono strukturę algorytmu NPLAN [Ł14a]. Została ona zainspirowana suboptymalnym równaniem predykcji algorytmu NPL \eqref{w_ypred_npl}. Stosuje się dwie sieci neuronowe. Pierwsza z nich - aproksymator neuronowy - na bieżąco wyznacza dla aktualnego punktu pracy współczynniki odpowiedzi skokowej \(s_1(k),\ldots,s_N(k)\), które są elementami macierzy dynamicznej \(\boldsymbol{G}(k)\). W algorytmie NPLAN nie ma więc potrzeby bieżącej, cyklicznej linearyzacji modelu i obliczania współczynników odpowiedzi skokowej. Druga sieć jest zwykłym dynamicznym modelem neuronowym. Model ten jest stosowany wyłącznie do obliczania nieliniowej trajektorii swobodnej \(\boldsymbol{y}^{0}(k)\).
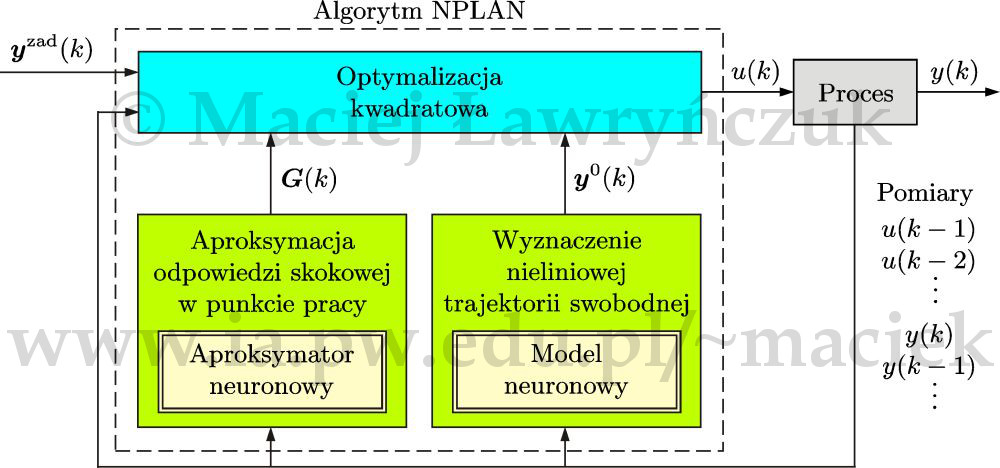
Punkt pracy (wejścia aproksymatora neuronowego) określony jest przez wektor pomiarów $$ %\begin{equation} \widetilde{\boldsymbol{x}}(k)=\left[u(k-1) \ldots u(k-\tilde{n}_{\mathrm{B}}) \ y(k) \ldots y(k-\tilde{n}_{\mathrm{A}}) \right]^{\mathrm{T}} \nonumber %\end{equation} $$ Aproksymator jest statycznym modelem neuronowym, nie występuje w nim rekurencja. Dzięki temu jego uczenie jest proste, nie występują problemy związane z propagacją błędów predykcji. Istnieją trzy metody generacji danych potrzebnych do identyfikacji aproksymatora:
- Dynamiczny model neuronowy jest symulowany w pętli otwartej. W trakcie symulacji model jest sukcesywnie linearyzowany dla aktualnego punktu pracy, obliczane są współczynniki odpowiedzi skokowej modelu zlinearyzowanego.
- Dynamiczny model neuronowy jest wykorzystany w klasycznym algorytmie NPL. Algorytm ten jest symulowany (lub uruchamiany z rzeczywistym procesem) dla serii skoków wartości zadanej. Podczas pracy algorytmu model jest sukcesywnie linearyzowany dla różnych punktów pracy, wyznaczane są współczynniki odpowiedzi skokowej modelu zlinearyzowanego.
- Dla różnych punktów pracy rejestruje się odpowiedzi skokowe procesu.
W pracy [Ł11d] omówiono zastosowanie algorytmu NPLAN w układzie regulacji niskociśnieniowej kolumny destylacyjnej.
Analityczny algorytm NPLAN
W klasycznym analitycznym algorytmie NPL optymalny (bez ograniczeń) wektor przyrostów sygnałów sterujących dla aktualnej iteracji wyraża się wzorem \begin{equation} \triangle u(k|k)=\boldsymbol{K}^{n_{\mathrm{u}}}(k)(\boldsymbol{y} ^{\mathrm{zad}}(k)-\boldsymbol{y}^{0}(k))\label{w_du_Knu_yzady0_nplanal} \end{equation} gdzie macierz \(\boldsymbol{K}^{n_{\mathrm{u}}}(k)\) składa się z \(n_{\mathrm{u}}\) pierwszych wierszy macierzy \(\boldsymbol{K}(k)\), która z kolei jest funkcją macierzy dynamicznej \(\boldsymbol{G}(k)\) modelu zlinearyzowanego w aktualnym punkcie pracy.
W analitycznym algorytmie NPLAN [Ł14a, Ł14b], którego struktura została przedstawiona na rys. 24, analogicznie jak w algorytmie numerycznym NPLAN, stosuje się dwie sieci neuronowe: aproksymator neuronowy oraz klasyczny (dynamiczny) model neuronowy. Aproksymator neuronowy wyznacza dla aktualnego punktu pracy macierz \(\boldsymbol{K}^{n_{\mathrm{u}}}(k)\), bez potrzeby jawnej linearyzacji modelu, obliczania jego odpowiedzi skokowej i rozkładu macierzy, natomiast model neuronowy służy do wyznaczania nieliniowej trajektorii swobodnej.
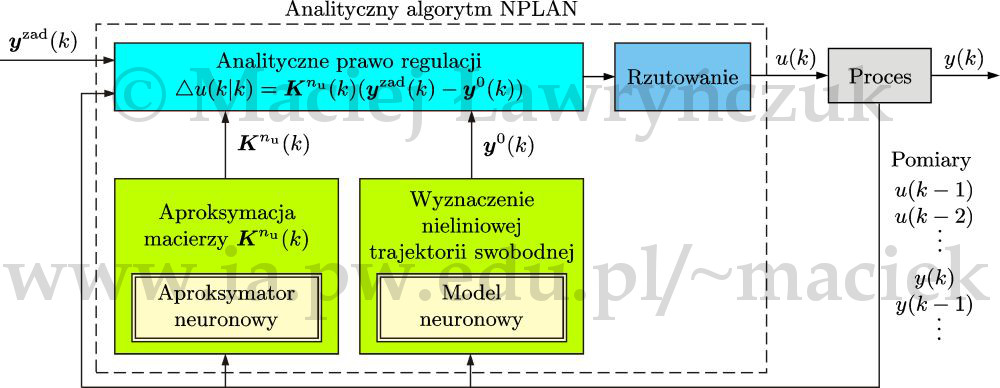
Dzięki zastosowaniu aproksymatora neuronowego analityczny algorytm NPLAN jest bardzo mało złożony obliczeniowo. O ile w wersji numerycznej algorytmu unika się jedynie cyklicznej linearyzacji i przeliczania odpowiedzi skokowej (ale rozwiązuje się kwadratowe zadanie optymalizacji), to w wersji analitycznej nie ma ani linearyzacji, ani obliczania odpowiedzi skokowej, ani rozkładu macierzy, gdyż aproksymator neuronowy bezpośrednio oblicza aktualne współczynniki prawa regulacji.
Można podać dwie metody generacji danych potrzebnych do identyfikacji aproksymatora:
- Dynamiczny model neuronowy jest symulowany w pętli otwartej. W trakcie symulacji model jest sukcesywnie linearyzowany dla aktualnego punktu pracy, obliczane są współczynniki odpowiedzi skokowej modelu zlinearyzowanego oraz macierz \(\boldsymbol{K}^{n_{\mathrm{u}}}(k)\).
- Dynamiczny model neuronowy jest wykorzystany w klasycznym (analitycznym) algorytmie NPL. Algorytm ten jest symulowany (lub uruchamiany z rzeczywistym procesem) dla serii skoków wartości zadanej. Podczas pracy algorytmu model jest sukcesywnie linearyzowany dla różnych punktów pracy, wyznaczane są współczynniki odpowiedzi skokowej modelu zlinearyzowanego, wyznaczana jest macierz \(\boldsymbol{K}^{n_{\mathrm{u}}}(k)\).
W pracy [Ł14b] omówiono zastosowanie analitycznego algorytmu NPLAN w układzie regulacji wysokociśnieniowej kolumny destylacyjnej etylen-etan.
6.2. Algorytm NPLT z Aproksymacją Neuronową (NPLTAN)
Aproksymacja neuronowa może być również zastosowana w algorytmie NPLTAN [Ł14a]. W klasycznym algorytmie NPLT nieliniowy model procesu jest na bieżąco linearyzowany wokół założonej trajektorii \(\boldsymbol{u}^{\mathrm{traj}}(k)\). W najprostszym przypadku (algorytm \(\mathrm{NPLT}_{\boldsymbol{u}(k-1)}\)) linearyzacja wykonywana jest wokół trajektorii zdefiniowanej przez sygnały sterujące zastosowane w poprzedniej iteracji (\(\boldsymbol{u}^{\mathrm{traj}}(k)=\boldsymbol{u}(k-1)\)), czemu odpowiada trajektoria \(\hat{\boldsymbol{y}}^{\mathrm{traj}}(k)=\boldsymbol{y}^0(k)\). Równanie predykcji ma wówczas postać $$ \begin{equation} \hat{\boldsymbol{y}}(k)=\boldsymbol{H}(k)\boldsymbol{J}\triangle \boldsymbol{u}(k)+\boldsymbol{y}^0(k) \nonumber %\label{w3_zasada_superpozycji_nplt} \end{equation} $$ Macierz \(\boldsymbol{H}(k)\) zawiera pochodne prognozowanej trajektorii sygnałów wyjściowych względem przyszłej sekwencji sterującej. W klasycznym algorytmie \(\mathrm{NPLT}_{\boldsymbol{u}(k-1)}\) jest ona, podobnie jak trajektoria \(\hat{\boldsymbol{y}}^{\mathrm{traj}}(k)=\boldsymbol{y}^0(k)\), obliczana na podstawie pełnego modelu nieliniowego.
W algorytmie \(\mathrm{NPLT}_{\boldsymbol{u}(k-1)}\mathrm{AN}\) stosuje się dwie sieci: pierwsza z nich jest aproksymatorem neuronowym, który na bieżąco wyznacza elementy macierzy \(\boldsymbol{H}(k)\) w aktualnym punkcie pracy, natomiast druga sieć jest dynamicznym modelem neuronowym i służy do obliczania trajektorii swobodnej \(\boldsymbol{y}^0(k)\). Struktura algorytmu jest bardzo podobna do pokazanej na rys. 23 struktury algorytmu NPLAN (ale zamiast macierzy \(\boldsymbol{G}(k)\) wyznacza się macierz \(\boldsymbol{H}(k)\)).
Dane wykorzystywane do identyfikacji aproksymatora neuronowego można otrzymać podobnie jak w dwóch pierwszych metodach stosowanych w trakcie syntezy algorytmu NPLAN: macierz \(\boldsymbol{H}(k)\) obliczana jest w wyniku symulacji modelu i linearyzacji w pętli otwartej lub w trakcie symulacji (uruchomienia z rzeczywistym procesem) klasycznego algorytmu NPLT dla serii skoków wartości zadanej.
Analityczny algorytm NPLTAN
W klasycznym analitycznym algorytmie \(\mathrm{NPLT}_{\boldsymbol{u}(k-1)}\) optymalny (bez uwzględnienia ograniczeń) wektor przyrostów sygnałów sterujących ma postać taką samą jak w analitycznym algorytmie NPL (wzór \eqref{w_du_Knu_yzady0_nplanal}), ale macierz \(\boldsymbol{K}^{n_{\mathrm{u}}}(k)\) zależy od macierzy \(\boldsymbol{H}(k)\), zawierającej pochodne cząstkowe prognozowanej trajektorii sygnałów wyjściowych względem przyszłej sekwencji sterującej.
W analitycznym algorytmie \(\mathrm{NPLT}_{\boldsymbol{u}(k-1)}\mathrm{AN}\) [Ł14a, Ł14b] stosuje się dwie sieci neuronowe: pierwsza z nich jest aproksymatorem neuronowym, który na bieżąco wyznacza elementy macierzy \(\boldsymbol{K}^{n_{\mathrm{u}}}(k)\) w aktualnym punkcie pracy, bez potrzeby jawnej linearyzacji modelu i rozkładu macierzy, natomiast druga sieć jest zwykłym dynamicznym modelem neuronowym i służy do obliczania trajektorii swobodnej \(\boldsymbol{y}^0(k)\). Struktura algorytmu jest bardzo podobna do pokazanej na rys. 23 struktury algorytmu NPLAN (ale macierz \(\boldsymbol{K}^{n_{\mathrm{u}}}(k)\) jest inna). Dane wykorzystywane do identyfikacji aproksymatora neuronowego można otrzymać podobnie jak w przypadku algorytmu analitycznego NPLAN.
W pracach [Ł14a, Ł14b] omówiono zastosowanie analitycznego algorytmu NPLAN w układzie regulacji wysokociśnieniowej kolumny destylacyjnej etylen-etan.
6.3. Algorytm DMC z Aproksymacją Neuronową (DMCAN)
Aproksymacja neuronowa może być również zastosowana w algorytmie DMC [Ł14a, Ł10e]. Klasyczny (liniowy) model odpowiedzi skokowej ma postać $$ \begin{equation} y(k)=y(0)+\sum_{j=1}^{k}s_j\triangle u(k-j) \nonumber \end{equation} $$ gdzie wielkości \(s_1,\ldots,s_k\) są współczynnikami odpowiedzi skokowej. W algorytmie DMCAN stosowany jest neuronowy model odpowiedzi skokowej. Jego parametry nie są stałe, lecz zależą od aktualnego punktu pracy $$ \begin{equation} y(k)=y(0)+\sum_{j=1}^{k}s_j(k)\triangle u(k-j) \nonumber \end{equation} $$ Równanie predykcji algorytmu DMCAN ma postać $$ \begin{equation} \hat{\boldsymbol{y}}(k)=\boldsymbol{G}(k)\triangle\boldsymbol{u}(k) + \boldsymbol{y}(k)+\boldsymbol{G}^{\mathrm{p}}(k)\triangle\boldsymbol{u}^{\mathrm{p}}(k) %\nonumber \label{w_zasada_superpozycji_dmcan} \end{equation} $$ gdzie macierz \(\boldsymbol{G}(k)\), zawierająca aktualne współczynniki odpowiedzi skokowej (w aktualnym punkcie pracy), ma strukturą taką samą jak stosowana w algorytmie SL lub NPL, $$ \begin{equation} \boldsymbol{y}(k)=\left[ \begin{array}{c} y(k)\\ \vdots\\ y(k) \end{array} \right] , \ \triangle\boldsymbol{u}^{\mathrm{p}}(k)=\left[ \begin{array}{c} \triangle u(k-1)\\ \vdots\\ u(k-(D-1)) \end{array} \right] %\label{w2_Uk} \nonumber \end{equation} $$ są wektorami, odpowiednio, o długości \(N\) i \(D-1\), natomiast macierz $$ \begin{equation} \boldsymbol{G}^{\mathrm{p}}(k)=\left[ \begin{array} [c]{cccc}% s_{2}(k)-s_{1}(k) & s_{3}(k)-s_{2}(k) & \ldots & s_D(k)-s_{D-1}(k)\\[0.25mm] s_{3}(k)-s_{1}(k) & s_{4}(k)-s_{2}(k) & \ldots & s_{D+1}(k)-s_{D-1}(k)\\ \vdots & \vdots & \ddots & \vdots\\ s_{N+1}(k)-s_{1}(k) & s_{N+2}(k)-s_{2}(k) & \ldots & s_{N+D-1}(k)-s_{D-1}(k) \end{array} \right] \nonumber %\label{w7_dmcan_Gpk} \end{equation} $$ ma wymiary \(N \times N_{\mathrm{u}}\).
Wykorzystując równanie predykcji \eqref{w_zasada_superpozycji_dmcan}, w każdej iteracji algorytmu DMCAN rozwiązuje się zadanie optymalizacji kwadratowej \begin{align} &\begin{array}{l} \min\limits_{\triangle \boldsymbol{u}(k)} \Big \{ J(k)=\big \| \boldsymbol{y} ^{\mathrm{zad}}(k)-\boldsymbol{G}(k)\triangle\boldsymbol{u}(k)-\boldsymbol{y}(k) \boldsymbol{G}^{\mathrm{p}}(k)\triangle\boldsymbol{u}^{\mathrm{p}}(k) \|_{\boldsymbol{M}} ^{2}\nonumber\\ \qquad \qquad \qquad \quad +\left\| \triangle\boldsymbol{u}(k)\right\| ^{2}_{\boldsymbol{\Lambda}} \Big\} \\ \end{array}\nonumber\\ &\text{przy ograniczeniach}\label{w_zad_optdmcan}\\ &\boldsymbol{u}^{\min}\leq\boldsymbol{J}\triangle\boldsymbol{u}(k)+\boldsymbol{u}(k-1)% \leq\boldsymbol{u}^{\max}\nonumber\\ &-\triangle\boldsymbol{u}^{\max}\leq\triangle\boldsymbol{u}(k)\leq\triangle\boldsymbol{u}^{\max}\nonumber\\ &\boldsymbol{y}^{\min}\leq \boldsymbol{G}(k)\triangle\boldsymbol{u}(k)+\boldsymbol{y}(k)+\boldsymbol{G}^{\mathrm{p}}(k)\triangle\boldsymbol{u}^{\mathrm{p}}(k)\leq\boldsymbol{y}^{\max}\nonumber \end{align}
Struktura algorytmu DMCAN została pokazana na rys. 25. Wartości współczynników odpowiedzi skokowej obliczane są na bieżąco przez aproksymator neuronowy dla aktualnego punktu pracy. Aby przygotować dane do identyfikacji aproksymatora neuronowego należy zarejestrować odpowiedzi skokowe procesu dla różnych punktów pracy.
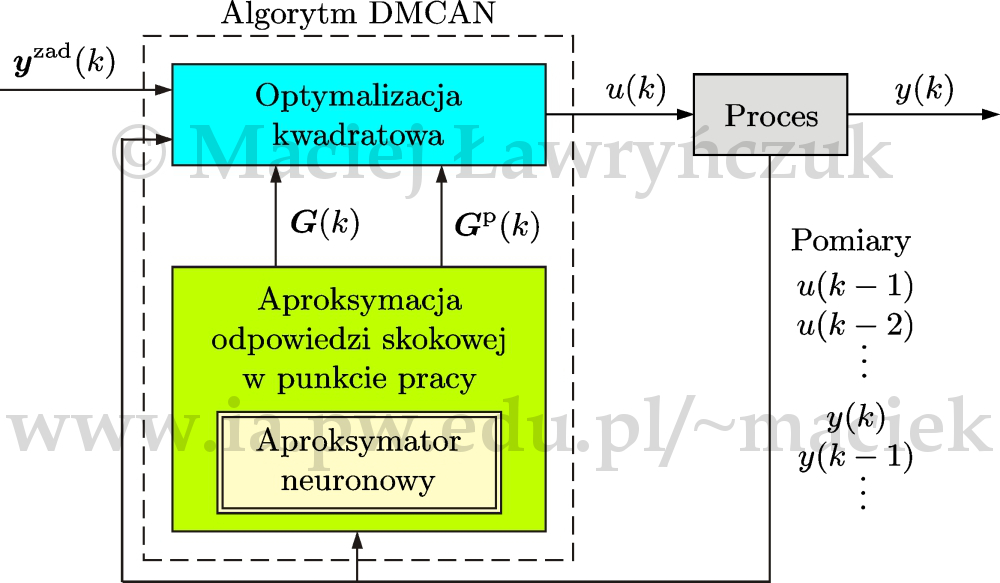
W pracy [Ł10e] omówiono zastosowanie algorytmu DMCAN w układzie regulacji reaktora polimeryzacji.
Analityczny algorytm DMCAN
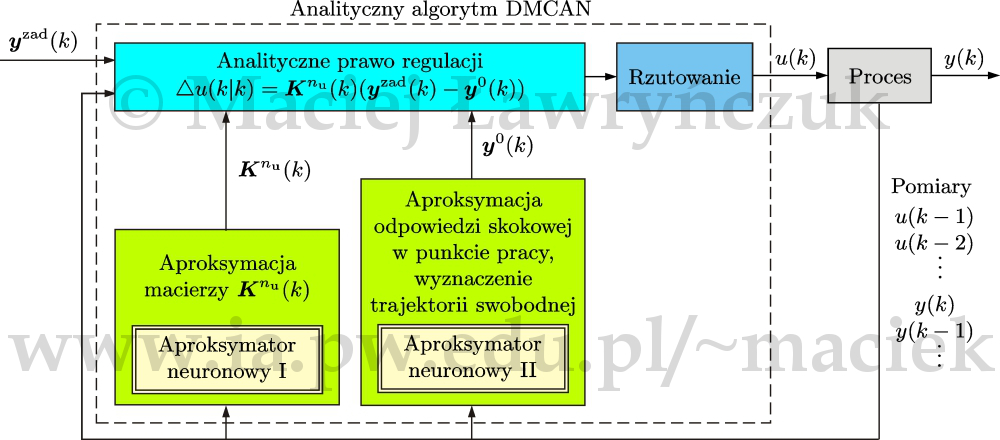
Algorytm DMCAN można również sformułować w postaci analitycznej [Ł14a]. Na podstawie zadania optymalizacji \eqref{w_zad_optdmcan}, pomijając ograniczenia, otrzymuje się problem \begin{align} &\begin{array}{l} \min\limits_{\triangle \boldsymbol{u}(k)} \Big \{ J(k)=\big \| \boldsymbol{y} ^{\mathrm{zad}}(k)-\boldsymbol{G}(k)\triangle\boldsymbol{u}(k)-\boldsymbol{y}(k) \boldsymbol{G}^{\mathrm{p}}(k)\triangle\boldsymbol{u}^{\mathrm{p}}(k)\big \|_{\boldsymbol{M}} ^{2}\nonumber\\ \qquad \qquad \qquad \quad +\left\| \triangle\boldsymbol{u}(k)\right\| ^{2}_{\boldsymbol{\Lambda}}\Big\} \\ \end{array}\nonumber \end{align} Przyrównując do zera (wektorowego) gradient minimalizowanej funkcji kryterialnej, otrzymuje się optymalny (bez uwzględnienia ograniczeń) wektor przyrostów sygnałów sterujących w postaci typowej dla algorytmu analitycznego NPL (wzór \eqref{w_du_Knu_yzady0_nplanal}), gdzie trajektoria swobodna opisana jest wzorem \begin{equation} \boldsymbol{y}^0(k)=\boldsymbol{y}(k)+\boldsymbol{G}^{\mathrm{p}}(k)\triangle\boldsymbol{u}^{\mathrm{p}}(k) %\nonumber \label{w_dmcanal_y0} \end{equation} Struktura analitycznego algorytmu DMCAN jest przedstawiona na rys. 26. Jego struktura jest podobna do pokazanej na rys. 24 struktury analitycznego algorytmu NPLAN, lecz stosuje się dwa aproksymatory neuronowe. Pierwszy z nich oblicza dla aktualnego punktu pracy macierz współczynników prawa regulacji. Drugi aproksymator wyznacza współczynniki odpowiedzi skokowej w aktualnym punkcie pracy, na ich podstawie oblicza się ze wzoru \eqref{w_dmcanal_y0} trajektorię swobodną. Do uczenia obu aproksymatorów wykorzystuje się te same dane, czyli odpowiedzi skokowe procesu dla różnych punktów pracy.

| Poprzednia strona: 5. Przykład 2: modelowanie i regulacja predykcyjna reaktora neutralizacji | Następna strona: 7. Współpraca algorytmów regulacji predykcyjnej i optymalizacji punktu pracy |